
基于音频的钢琴演奏难度打分
https://arxiv.org/abs/2403.03947
Can Audio Reveal Music Performance Difficulty? Insights from the Piano Syllabus Dataset
- 🎶 本研究通过引入PSyllabus数据集,首次解决了从音频录音中估计音乐演奏难度的挑战,该数据集包含7,901首钢琴曲,涵盖11个难度级别。
- 🎹 团队提出了一种基于CRNN的识别框架,能够处理CQT和piano-roll等不同音频输入表示,并发现piano-roll表示以及早期的多模态融合(MM)在难度估计任务中表现最佳。
- 📈 广泛的实验证明了多任务学习(特别是音乐时代识别)能提高模型泛化能力,同时整合多重演奏结果能增强预测的稳健性,为音乐教育和MIR领域提供了宝贵见解。
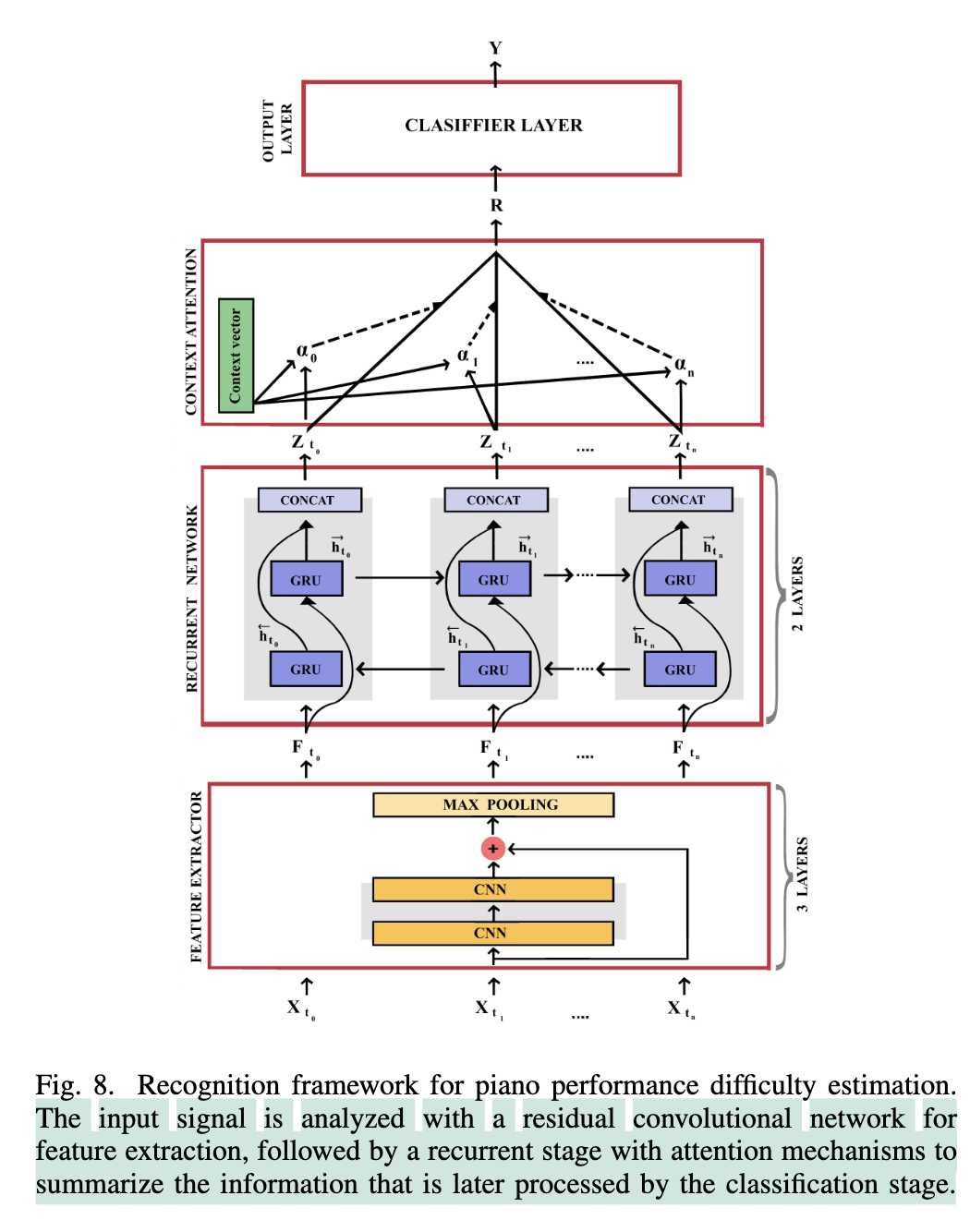
论文提出了一种利用音频记录自动估计音乐演奏难度的方法,旨在弥补现有音乐信息检索 (MIR) 领域中主要关注符号乐谱或乐谱图像的空白。
I. 引言与背景
在音乐教育领域,自动评估音乐作品的演奏难度对于个性化课程设计至关重要。尽管手动评估耗时且主观,但专业人士通常能在粗略范围内达成共识。MIR 领域的研究者已在此方面投入十余年努力,但主要集中于钢琴音乐,并使用如 MusicXML 格式的符号乐谱或乐谱图像作为信息源。现有的解决方案多将此任务视为分类问题,也有基于规则或分析的方法。然而,鉴于音乐的多模态特性,当前难度估计领域对记谱音乐的偏重限制了其应用范围。
本文旨在通过直接分析音频记录来填补这一空白,具有重要的教学和 MIR 意义。该方法面临三个核心挑战:
1. 缺乏带有难度标签的音频数据集。
2. 获取适合分析的音频信号表示。
3. 设计能够处理不同音频表示(无论是单模态还是多模态)的深度学习框架。
II. PSyllabus 数据集
为了解决数据稀缺问题,本文推出了 PSyllabus 数据集,这是首个基于音频的难度估计数据集。该数据集从 Piano Syllabus 社区收集,经过精心策划和清洗:
* 数据收集与整理: 从 Piano Syllabus 网站的 12,000 首作品中,通过 YouTube 检索到 9,829 首。通过过滤低质量录音、超出范围的曲目(如二重奏)、以及去除具有多个难度等级的相同作品后,剩余 8,426 首。为了解决同一录音在作品中难度不一致(例如,肖斯塔科维奇的 Op. 34 前奏曲中的不同难度)或标注与实际视频不符(例如,奏鸣曲的完整标注链接到单乐章视频)的问题,作者利用 ChatGPT (version 4) 通过提示工程(如 Fig. 2 和 Fig. 3 所示)验证了标注的一致性。最终,PSyllabus 数据集包含 7,901 首钢琴作品。
* 数据分析与统计:
* PSyllabus 是目前最大的难度估计数据集,包含 7,901 首作品,涵盖 11 个难度等级,来自 1,233 位作曲家,且平均不平衡比率 (Average Imbalance Ratio, AIR) 接近 1,表明类别分布均衡。
* 作品的音乐时代分布显示,浪漫主义时期和 20 世纪西方古典音乐的作品最多,现代时期也有显著存在。
* 作曲家分布呈长尾效应,D. Scarlatti、F. Liszt、J. S. Bach 和 F. Chopin 等少数作曲家占比较大,但也有大量其他作曲家的作品。
* 难度等级分布方面,男性作曲家的作品覆盖所有等级,在 10 级作品最多;女性作曲家的作品则集中在 3 级左右,但女性作曲家作品占比超过 14%,这对于通常被低估的女性作曲家群体来说是积极的。
* 通过 Kendall rank correlation coefficient (\tau_c) 与其他知名考试委员会的难度排名(如 ABRSM、Trinity 等)进行比较,PSyllabus 与其他排名的一致性很高,平均 \tau_c = 0.81,证明了其标注的可靠性。
* 基准数据集:
* Hidden Voices 数据集: 包含 57 首作品,7 个难度等级,主要来自被低估的黑人女性作曲家。
* Multiple Performances 数据集: 包含 55 首作品(每个难度等级一首,每首有 5 个不同演奏版本),用于评估不同演奏版本融合对难度预测的影响。
III. 方法论
难度估计任务被建模为 序数分类(Ordinal Classification),也称 序数回归(Ordinal Regression)。
任务形式化
给定输入表示 X(声学录音)和目标难度空间 Y,模型学习函数 f: X \rightarrow Y。
对于样本 x_i \in X,难度级别 C 表示为多标签向量
y_i = [\lambda_1,\ldots,\lambda_C],其中 \lambda_j \in {0,1} 且满足
\lambda_j \le \lambda_{j-1},\; j>1,从而保证难度的序数关系。
最终难度级别通过
\zeta(y_i) = \arg\max_{l\in[1,C]}(|\lambda_j=1,\forall j\le l| = l)
得到。
输入表示
论文比较两种音频表示方法:
- 谱中层表示 (Spectral Mid-level Representation)
使用 Constant-Q Transform (CQT),包含 88 个音高分箱,每八度 12 bins,hop length = 160。 - 钢琴卷帘表示 (Piano Roll Representation)
通过 Kong 等人的 AMT 方法(在 MAESTRO 数据集上预训练)获得,包括:- frame-wise pitch activations
- onset information
输出空间固定为 88 个音符。
两种表示统一为
X \in \mathbb{R}^{b \times t \times c},其中 b 为音高分箱数,t 为时间步长,c 为通道数(CQT=1,Piano Roll=2)。所有表示在时间维度下采样到 5 fps。
识别框架
模型采用 CRNN (Convolutional Recurrent Neural Network):
- 输入:x \in \mathbb{R}^{b \times t \times c}
- CNN(含残差连接)提取特征
x_f \in \mathbb{R}^{b’ \times t’ \times c’} - 特征重塑:
F = {F_0,\ldots,F_n} \in \mathbb{R}^{t’ \times (b’c’)} - GRU 层:
Z = {Z_0,\ldots,Z_n} \in \mathbb{R}^{t’ \times m} - Context Attention:汇聚为向量
R \in \mathbb{R}^m - 分类器:输出难度向量 \hat{y} \in \mathbb{R}^C
推理阶段对 \hat{y} 的每个元素使用 0.5 阈值。若使用多任务学习,模型包含多个分类或回归头。
多模态方法
Early Fusion
将 x_{cqt} \in \mathbb{R}^{b \times t \times 1} 与
x_{pr} \in \mathbb{R}^{b \times t \times 2} 在通道维拼接得到
x_{mm} \in \mathbb{R}^{b \times t \times 3},再输入 CRNN。
Late Fusion
分别训练 CQT 和 Piano Roll 模型,在推理阶段平均预测结果:
$\hat{y}{ensemble} = (\hat{y}{CQT} + \hat{y}_{PR})/2$
V. 实验结果
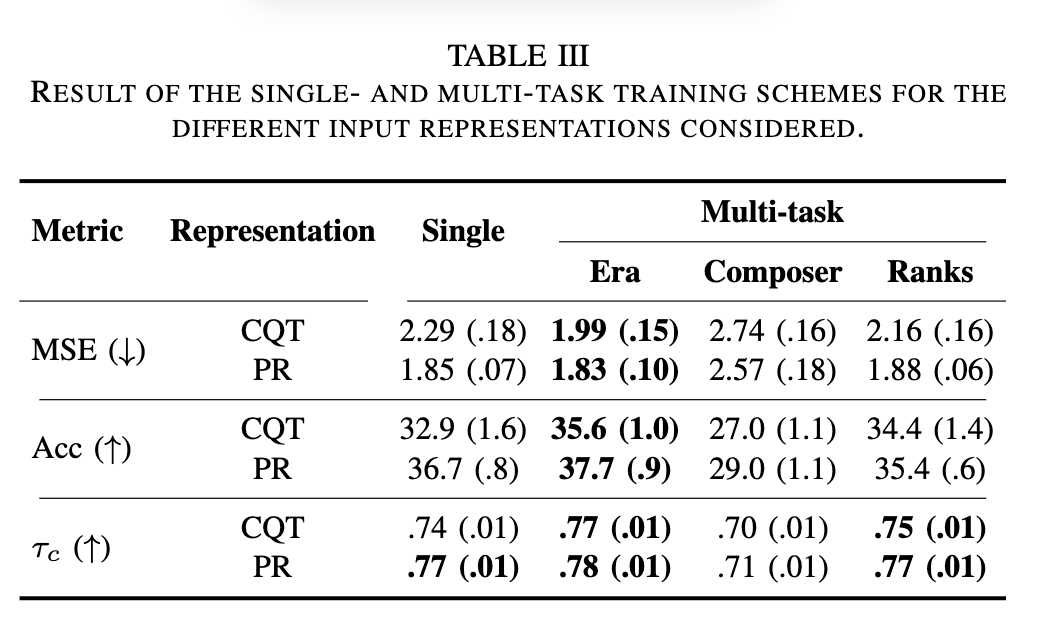
- A. 输入表示分析 (Table II):
- 在单模态场景中,钢琴卷帘 (PR) 在所有评估指标上均优于 CQT 表示,表明符号级表示(PR)对于难度估计任务更有效。
- 多模态场景下,早期融合 (MM) 方案表现最佳,略优于后期融合 (ENSEMBLE),显示了早期融合更有效地利用模态互补性。
- 本文结果表明,音频模态比符号或乐谱图像模态更具挑战性,因为其性能指标低于现有文献。
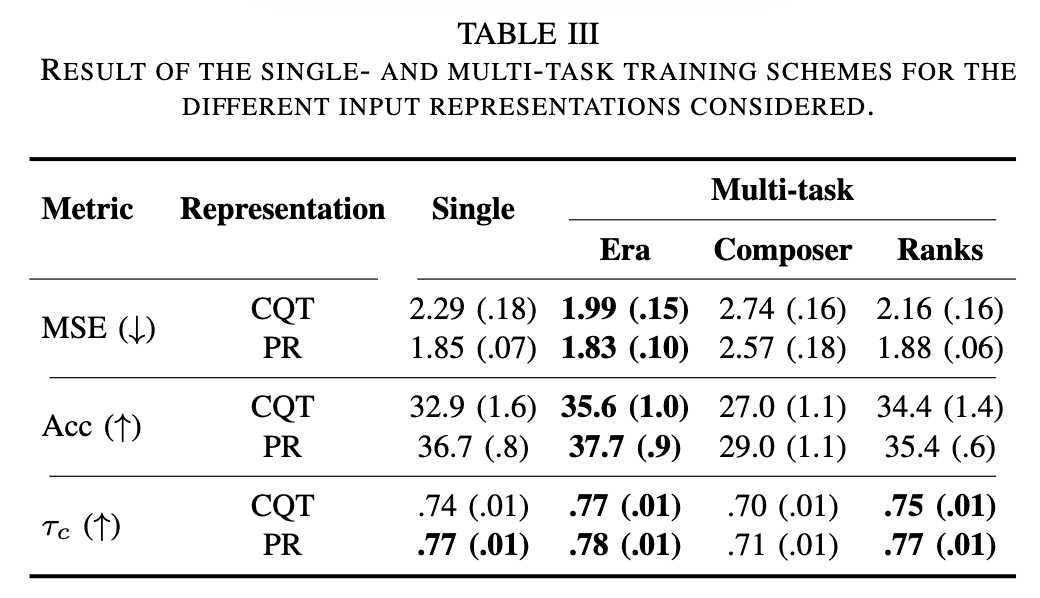
* B. 多任务训练方案 (Table III):
* 音乐时代分类任务的整合在所有训练场景中均取得了最佳性能提升,尤其是在准确率方面。
* 作曲家识别任务未能带来任何性能提升,甚至低于单任务基线,这可能是由于不同作曲家的多样化风格阻碍了模型的泛化能力。
* 多个排名任务的整合结果不一,虽有小幅提升,但不如时代分类任务显著,与一些乐谱图像研究的结论相悖。
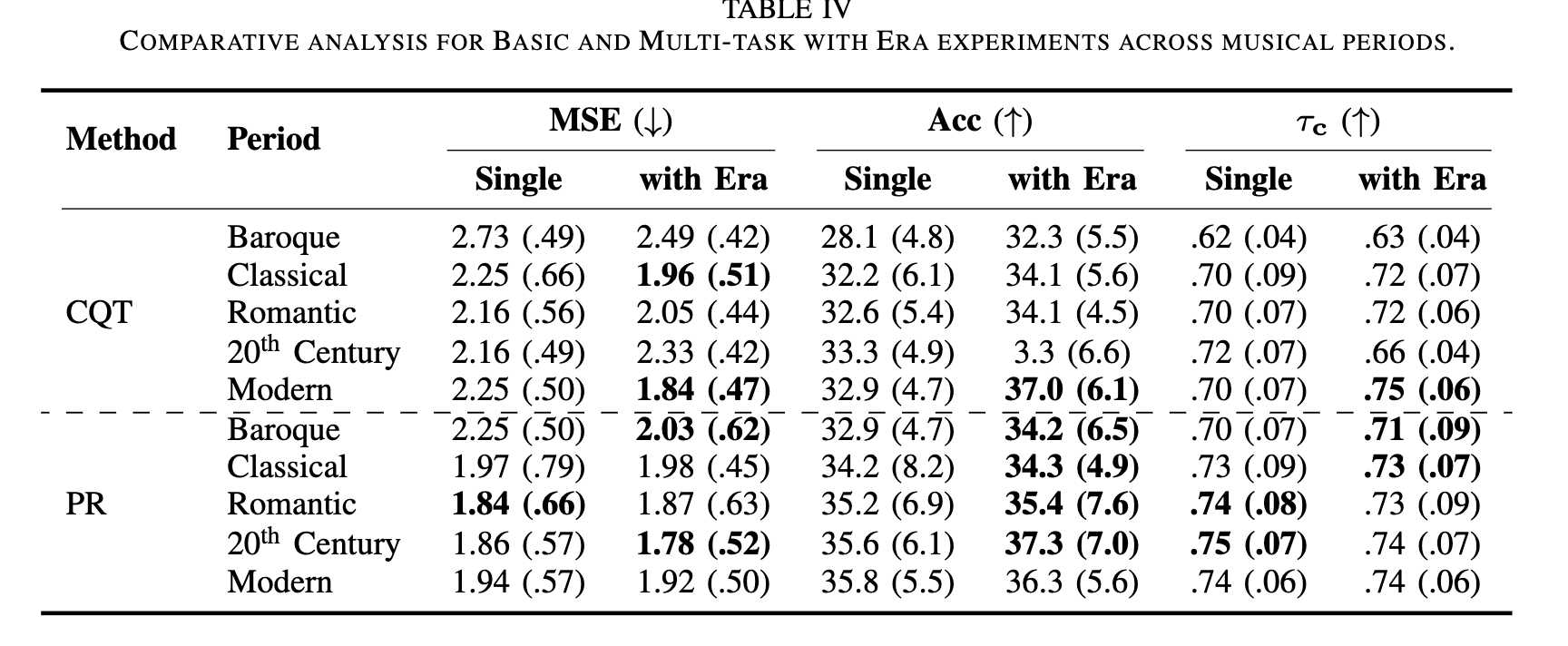
* 1) 音乐时代对难度估计的影响 (Table IV):
* 将音乐时代识别作为多任务方法的一部分,在巴洛克、古典、浪漫和现代时期均提高了模型的性能,表明时代特定的特征在音乐难度预测中具有重要意义。
VI. 女性作曲家案例研究
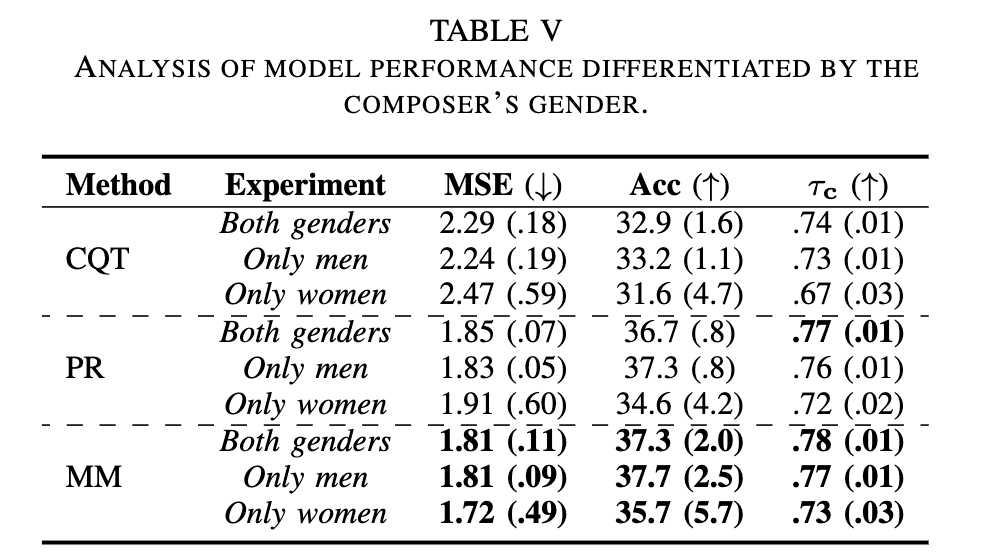
* A. 模型在女性作曲家作品上的表现 (Table V):
* MM 模型在混合性别数据上表现最佳,但测试女性作曲家作品时性能显著下降。尽管 MSE 较低,但 MSE 和准确率的标准差显著较高。这暗示模型对女性作曲家作品的预测在粗粒度上与真实值接近,但在细粒度上存在偏差。这可能源于音乐特征的固有差异或难度标注中存在的潜在偏见。
- B. Hidden Voices 零样本实验 (Table VI):
- 模型在 PSyllabus 数据集(11 个难度标签)上训练,并在 Hidden Voices 数据集(7 个难度标签)上进行零样本评估。PR 表示依然最具竞争力。
- 多任务训练(时代或排名)提高了 \tau_c 值,这凸显了多任务训练方案在零样本评估场景中减少性能损失的潜力。
VII. 多重演奏案例研究
本节研究了利用音乐作品的不同演奏版本(由不同演奏者演奏的多个录音)来提高整体识别结果的有效性。假设对给定音乐作品的不同演奏版本的难度得分进行决策级融合 (decision-level fusion) 可以获得更稳健的估计。
* 方法: 对于每首作品的 5 个随机演奏版本,计算难度估计集合,并评估均值 (mean)、中位数 (median) 和众数 (mode) 作为整合这些独立估计的统计指标。
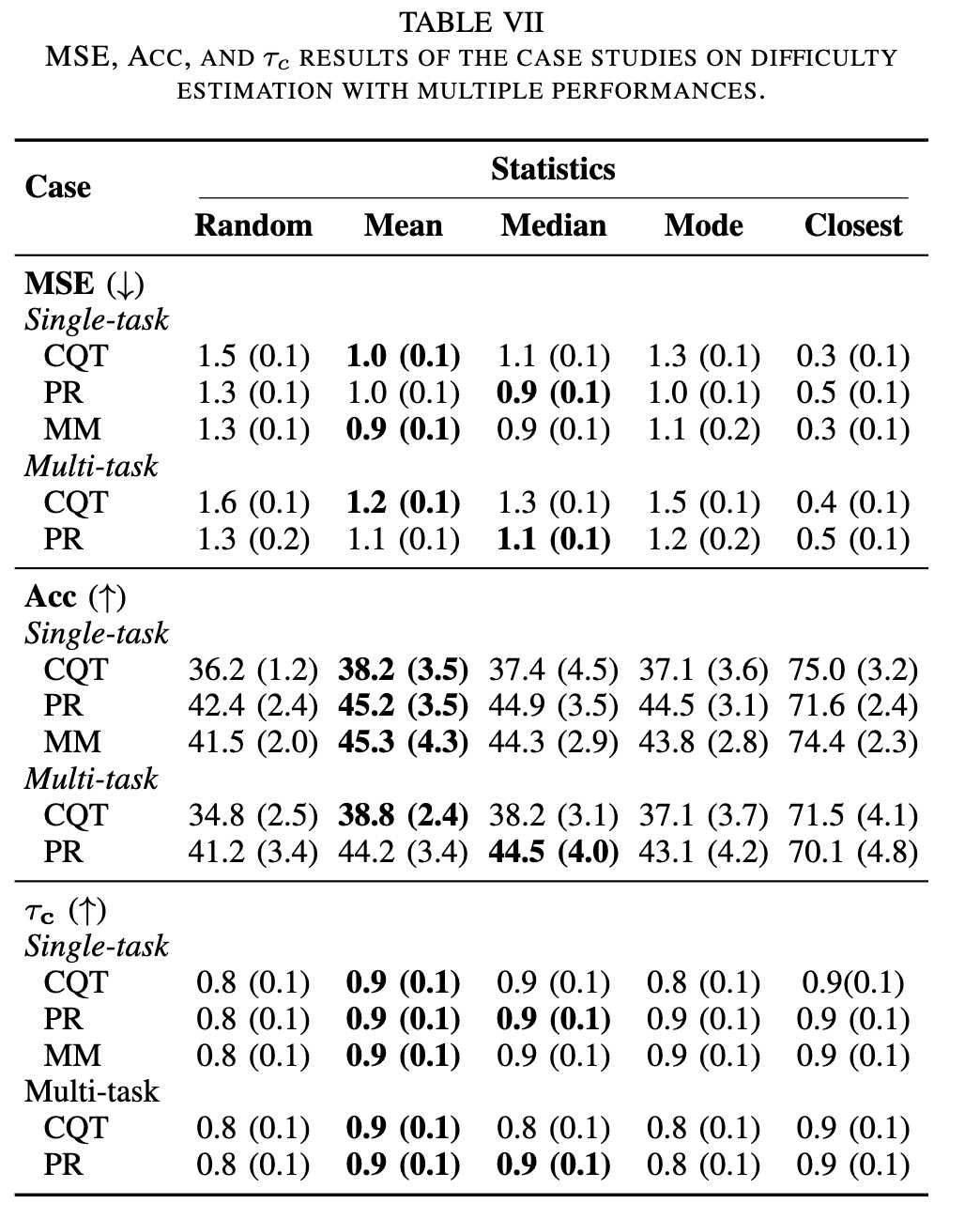
* 结果 (Table VII):
* 均值操作符是最佳的整合策略,在大多数情况下获得了最佳识别率。
* 中位数操作符也表现良好,但不如均值。
* 众数操作符在整合独立估计方面没有优势。
* 所有提出的整合策略均优于随机选择基线,表明特定的整合策略对于任务的成功至关重要。
* 多任务(含音乐时代)在此案例研究中未显示出显著优势。
VIII. 结论与未来工作
本文旨在弥合音乐难度估计领域中音频分析的空白,并做出了两项主要贡献:PSyllabus 数据集(首个基于音频的难度估计数据集)以及一个能够处理多种音频输入表示的识别框架。广泛的实验证明了该任务的可行性以及模型在零样本识别场景中的鲁棒性。所有代码、模型和数据均已公开,以促进音乐教育领域的协作。
未来工作计划:
* 通过提供作品的真实转录数据来研究该难度估计框架的性能上限。
* 考虑采用表示学习技术来更好地捕捉钢琴演奏特征。
* 探索更细粒度的难度估计(例如,音乐动机、段落级别),而非目前的全局得分。
* 将数据集与其他模态(如符号音乐表示、乐谱图像和文本描述)对齐,以创建多模态数据集。
* 探索可解释性框架,以便音乐教育者可以基于模型提供有价值的课程开发见解。
* 让教育者参与到任务中,以确保解决方案的实用性和影响力。
About Author
JOANNA JIANG
未来程序员,一般好看,热爱新事物。