
探索不同decoder head在midi 多属性序列结码的工作
一篇关于midi decoder解码器的科普工作,https://github.com/JudeJiwoo/nmt
Nested Music Transformer:在符号音乐与音频生成中顺序解码复合 Token
Jiwoo Ryu,Hao-Wen Dong,Jongmin Jung,Dasaem Jeong
1 韩国西江大学 人工智能系
2 加州大学圣地亚哥分校
3 韩国西江大学 艺术与技术系
摘要
使用复合 token 表示符号音乐,即每个 token 由多个不同的子 token 组成,每个子 token 表示一种独立的音乐特征或属性,这种表示方式的优势在于可以减少序列长度。虽然已有研究验证了复合 token 在音乐序列建模中的有效性,但若同时预测所有子 token,可能无法充分捕捉它们之间的相互依赖关系,从而导致次优结果。
本文提出了 Nested Music Transformer(NMT),这是一种专为自回归解码复合 token 而设计的架构。该架构类似于对展平 token 的处理方式,但内存消耗较低。NMT 由两个 Transformer 组成:一个主解码器用于建模复合 token 的序列,另一个子解码器用于建模每个复合 token 内部的子 token。实验结果表明,在多个符号音乐数据集以及 MAESTRO 数据集的离散音频 token 上,采用 NMT 处理复合 token 可以在困惑度(perplexity)方面取得更优表现。
- 引言
自回归语言模型在各类生成任务中已占据主导地位,包括音乐生成。语言模型一直是符号音乐生成中最广泛使用的生成模型。随着向量量化或残差向量量化技术的成功,语言模型也被广泛应用于音频域音乐生成。
语言模型的优势来源于其对序列信息的自回归建模能力。一旦数据被展平为离散 token 序列,语言模型便可直接应用。已有许多工作将符号音乐表示为展平 token 序列,例如 MIDI-like 编码或 REMI 编码。
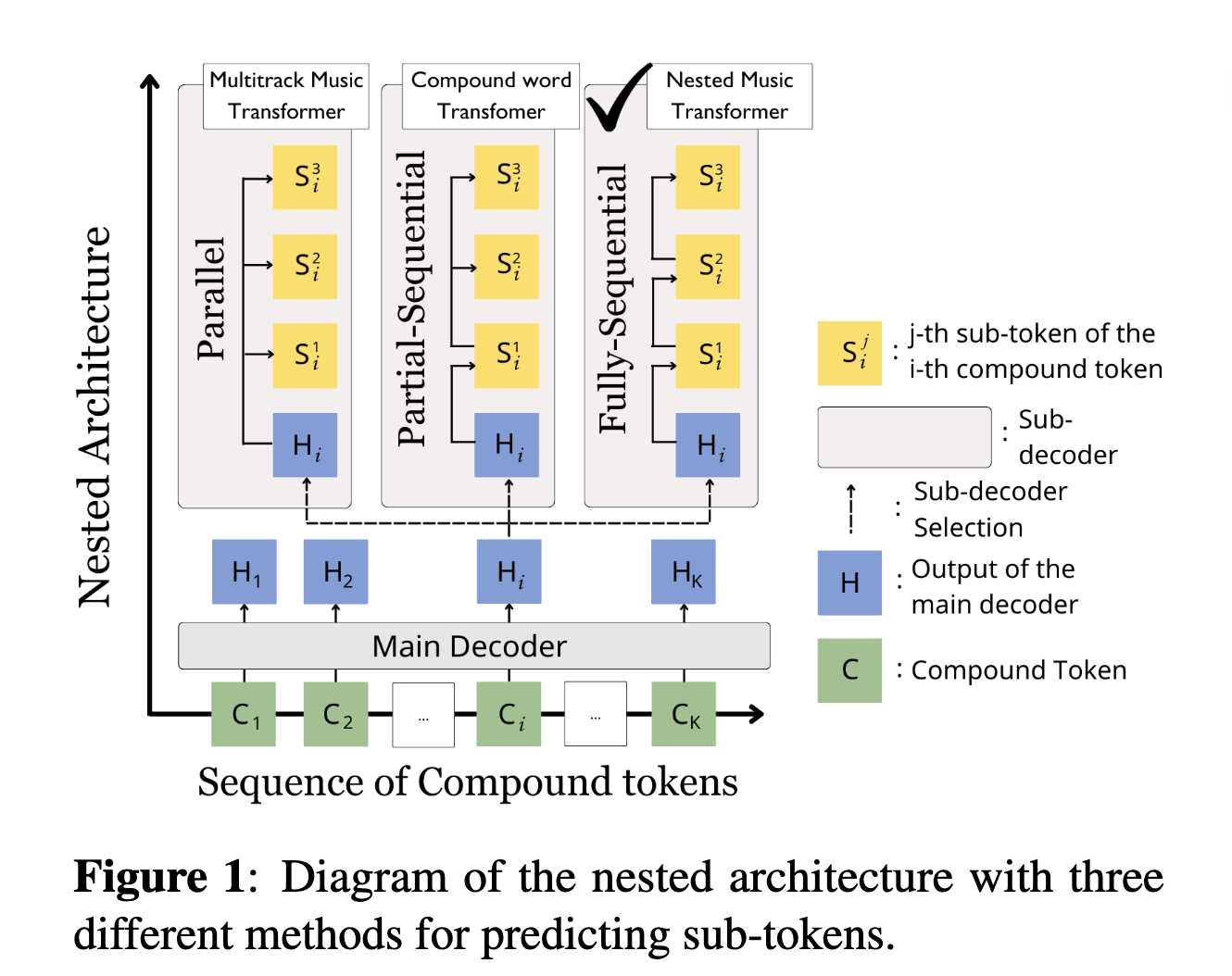
然而,这种方法的一个局限在于序列长度较长。例如,在 Lakh MIDI 数据集中,作品的平均 token 数量达到 14,647 个。为了解决这一问题,Compound Word Transformer 提出了一种名为 Compound Word 的编码方式,将多个音乐特征编码为一个多维复合 token。通过将音乐特征分为“节拍类”和“音符类”两种复合 token 类型,该方法将序列长度缩短至 REMI 的一半以下。类似地,Multitrack Music Transformer 将拍位、乐器、音高和时值编码为单一 token,使序列长度约为 REMI 的三分之一。此外,音符级别的复合 token 在风格识别或伴奏建议等判别任务中表现出明显优势。
尽管这些方法通过打包音乐特征以减少序列长度,但在符号音乐生成任务中,像 REMI 这样的展平编码仍然占主导地位。在部分研究的主观听感测试中,REMI 的生成效果更受偏好。原因之一在于,现有模型在预测复合 token 时采用并行或部分顺序预测方式,而未充分考虑复合 token 内部不同音乐特征之间的依赖关系。
为了解决这一问题,我们提出了一种新的解码框架——Nested Music Transformer(NMT)。该框架的主要目标是在保持高效内存使用的同时,以完全顺序的方式解码复合 token。NMT 在其子解码器中结合了两种交叉注意力结构:intra-token decoder 和 Embedding Enricher。前者用于自回归地解码单个复合 token 内部的子 token,后者通过关注前序复合 token 的隐藏状态来更新每个子 token 的 embedding。
我们证明,所提出的架构在性能上可与展平编码模型相媲美,同时在 GPU 内存使用和训练时间方面更加高效。这一结论通过符号音乐生成的定量评估与主观听感测试得到验证。此外,我们还在离散音频 token 上进行了实验,结果表明 NMT 及其他嵌套结构在音频生成任务上也能达到与强基线模型相当的表现。
- 基于音符的编码(Note-Based Encoding)
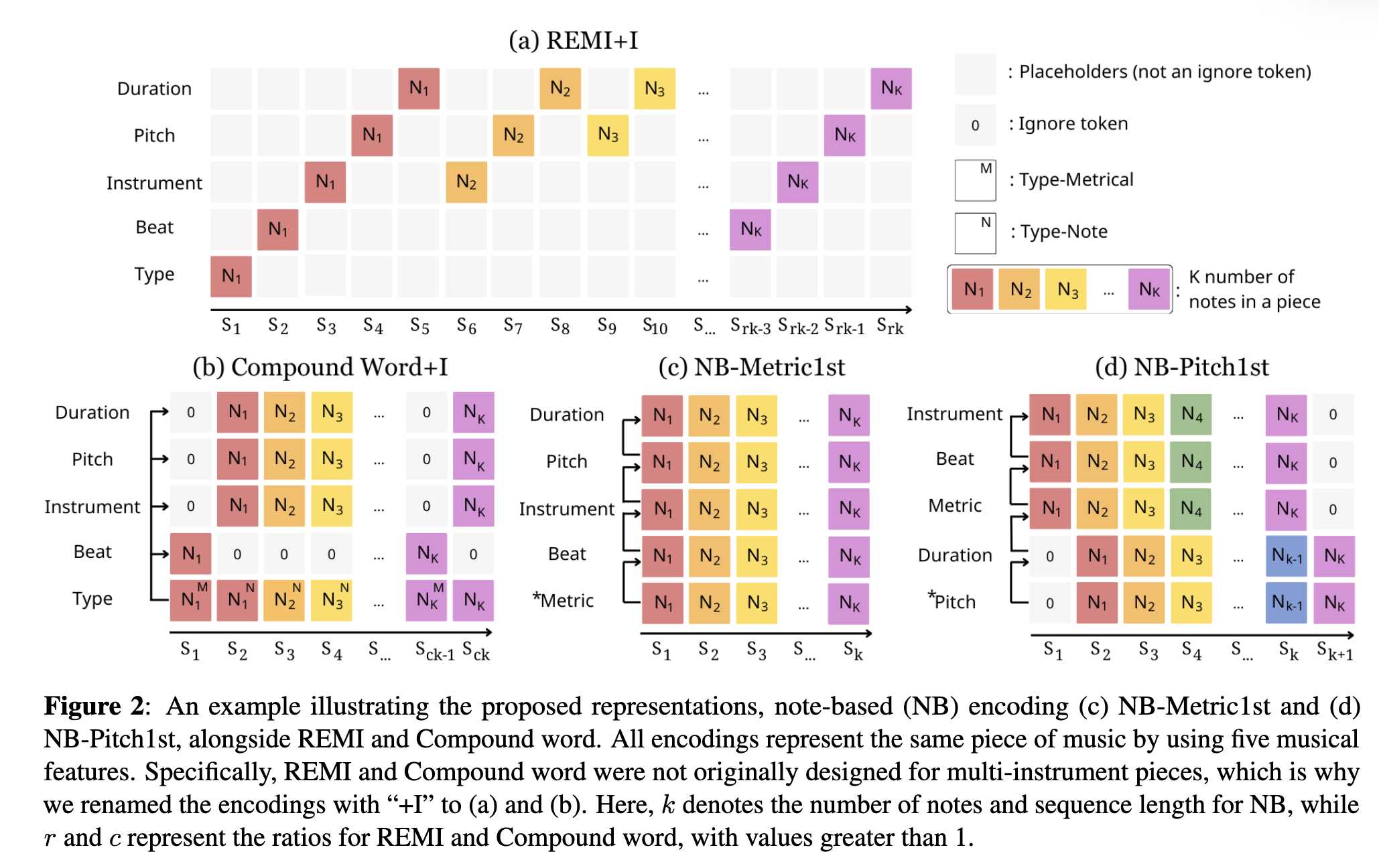
在介绍 Nested Music Transformer 之前,我们首先说明本文采用的复合 token 编码方式——Note-based encoding(NB)。NB 的特点是能够在单个复合 token 中包含最全面的音乐特征。
REMI、Compound Word 和 NB 都使用多种音乐特征来表示音乐。本文共使用八种特征:拍位、音高和时值为基本特征,乐器、和弦、速度和力度根据数据集特性选择性使用。此外,还使用一个额外特征 Metric(或 Type)来表示小节边界或拍号变化。
在 Compound Word 中,音乐特征被分为“节拍类”和“音符类”两组,并通过 Type token 指示类别。而 NB 不需要这种分组标识。由于 NB 中每个音符 token 都带有拍位信息,因此我们设计了 Metric 特征来编码节拍结构变化。Metric 指示当前音符是否引入新的拍号、小节或拍位,或延续前一节拍结构。我们定义了四种不同的 Metric 取值以表示不同的节拍变化组合。
Beat 表示音符在小节内的相对位置。Chord 通过规则算法获得。Tempo 采用指数刻度表示速度变化。Instrument 指示演奏音符的乐器,限制为 61 类。Pitch 使用 MIDI 的 128 种音高。Duration 表示音符持续时间。Velocity 表示 MIDI 力度。
对于 NB 编码,一首包含 K 个音符的乐曲可以表示为 K 个复合 token 序列,每个 token 包含如下子 token:
(metric, beat, chord, tempo, instrument, pitch, duration, velocity)
2.2 复合移位(Compound Shift)
通过重新排列子 token 的顺序,可以将目标子 token 放在首位预测,从而使其更多地依赖主解码器而非子解码器。例如,在 pitch-first 方案中,一个复合 token 的排列为:
(pitch, duration, velocity, metric, beat, chord, tempo, instrument)
需要注意的是,整体序列的预测顺序不变,仅改变复合 token 内部的分组边界。未移位表示为 NB-MF(metric-first),移位版本称为 NB-PF(pitch-first)。
- Nested Music Transformer
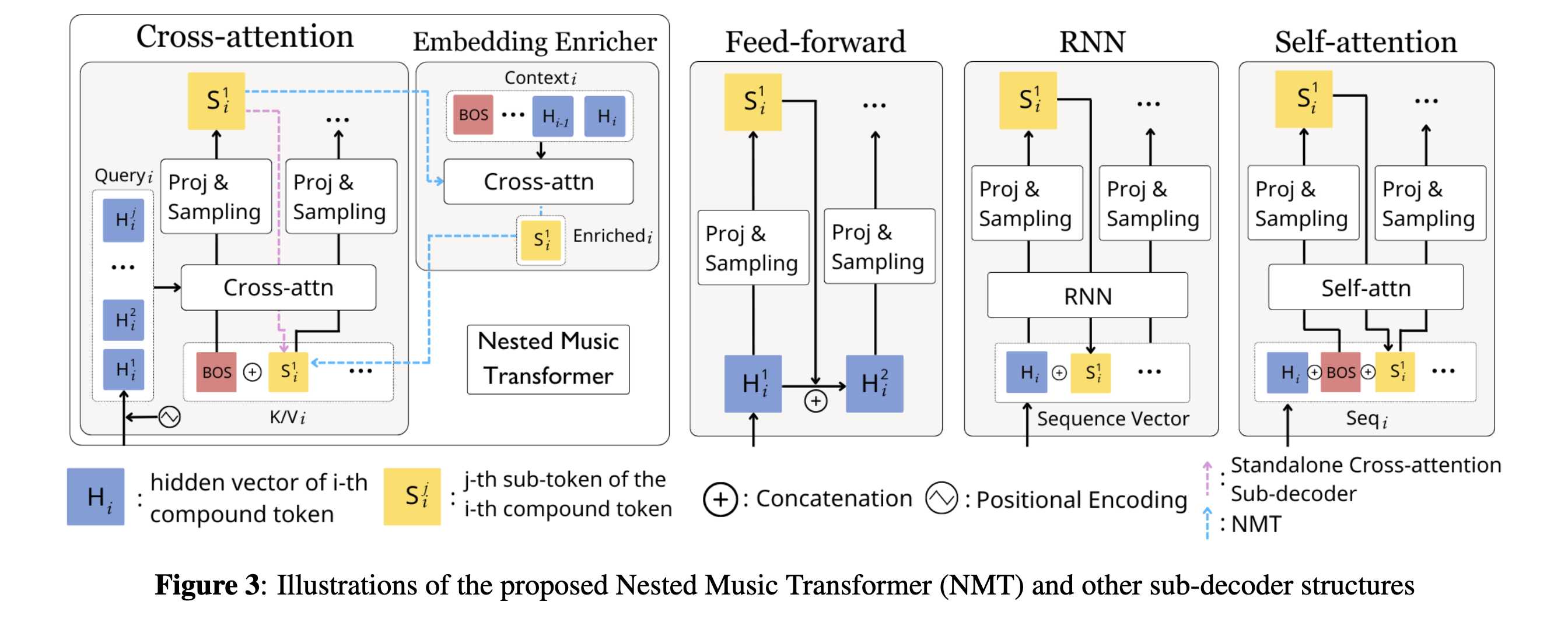
NMT 包含三个主要组件:token embedding、主解码器和子解码器。
首先,将每个子 token 的 embedding 在子 token 维度上求和,并加入可学习的绝对位置编码,得到复合 token 的表示。然后将其输入主解码器(decoder-only Transformer),得到隐藏向量 hi。
子解码器的目标是在给定主解码器输出 hi 和已生成子 token 的情况下,预测当前复合 token 的下一个子 token。
与以往使用拼接、RNN 或自注意力的方法不同,我们发现使用交叉注意力是建模复合 token 序列的有效方式。具体而言,子解码器通过迭代方式构建 key/value 序列,初始为 BOS token。对于第 j 个子 token,其查询向量为经过位置编码的 hi,key/value 为 BOS 加上已生成子 token 的 embedding。通过交叉注意力计算后,再通过线性变换与 softmax 得到预测概率。
Embedding Enricher
由于子 token embedding 相对浅层,我们设计了 Embedding Enricher,通过对过去 w 个主解码器隐藏状态进行交叉注意力,增强子 token embedding 的语义表达。实验表明,这种增强机制在符号音乐任务中带来更优的客观指标。
Self-attention 与 Cross-attention 比较
作者指出,主解码器输出 hi 已包含充足上下文信息,而子 token embedding 缺乏上下文。交叉注意力允许 hi 作为 key,从而形成更直接的梯度传播路径,因此优于自注意力更新 embedding 的方式。
- 实验
符号音乐实验使用 Pop1k7、Pop909、SOD 和 LMD clean 数据集。离散音频实验使用 MAESTRO 数据集,并将音频编码为 50Hz 采样率的离散 token,每个 token 包含 4 个 codebook。
模型规模约 4000 万参数(符号音乐)和 6200 万参数(音频)。使用 AdamW 优化器、cosine 学习率调度、Flash Attention 和混合精度训练。
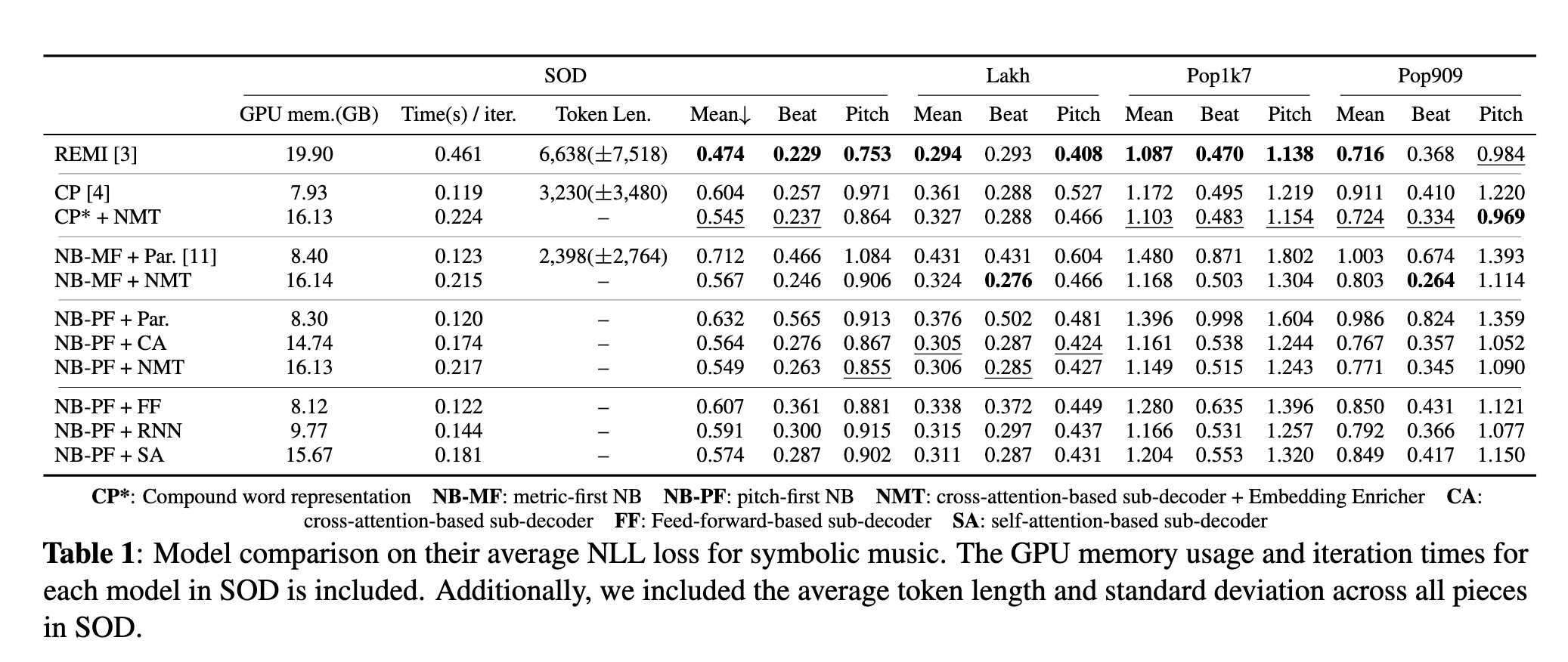
符号音乐评估采用平均负对数似然(NLL)。为公平比较不同编码方式,作者通过移动窗口方法并对概率进行校正,使其在相似上下文条件下进行比较。
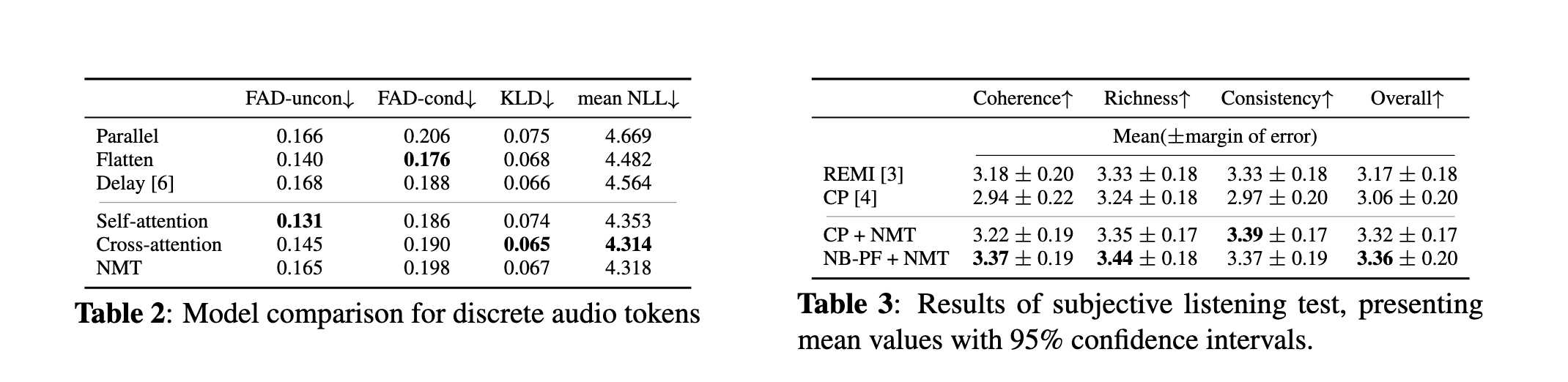
结果显示,NMT 在所有复合编码上均优于原模型结构。pitch-first 编码在音高预测上更优,而 metric-first 在拍位预测上更优。
在离散音频任务中,cross-attention 子解码器优于自注意力结构,但 Embedding Enricher 未带来显著改进。作者推测,这源于符号 token 与音频 token 在语义依赖结构上的差异。
主观听感测试结果表明,NB-PF + NMT 的整体质量与 REMI 相当,并优于 Compound Word。
- 结论
本文提出的 Nested Music Transformer 能够以顺序方式解码复合 token,在符号音乐和离散音频生成中均取得竞争性结果。该架构通过嵌套 Transformer 设计,同时解决了序列长度过长和特征依赖建模不足的问题,并在保持生成质量的前提下降低了训练成本。
About Author
JOANNA JIANG
未来程序员,一般好看,热爱新事物。