
音乐抄袭检测:任务建模与基于片段的解决方案
Music Plagiarism Detection: Problem Formulation and a Segment-Based Solution
Authors: Seonghyeon Go, Yumin Kim
Institution: MIPPIA Inc.
arXiv: 2601.21260v2
https://arxiv.org/abs/2601.21260
1. 研究背景与问题动机
音乐抄袭近年来成为高频法律与社会争议问题。现有 MIR 研究虽然涉及“相似性检测”,但缺乏对“音乐抄袭检测任务”本身的清晰定义,导致:
- 数据集构造不一致
- 评估标准混乱
- 与真实抄袭案例脱节
作者指出,当前许多工作使用人工构造数据进行训练(如 [3][4][5][6]),模型可能过拟合于“可计算相似性”,难以泛化到真实抄袭场景。
因此,本文的核心贡献是:
重新定义音乐抄袭检测任务,并提出一个基于片段转录(segment transcription)的系统框架。
2. 任务定义
作者明确区分了音乐抄袭检测与两个相近任务:
2.1 Cover Song Identification (CSI)
目标:判断整首歌是否为翻唱版本
典型方法:
- 旋律 MIDI 表示 [8]
- 序列匹配 [9]
- CNN 模型(Bytecover3)[10]
-
Conformer 结构(CoverHunter)[11]
2.2 Audio Fingerprinting
- 用于短音频片段识别整首歌
-
常用于流媒体识别 [12]
2.3 抄袭检测的特殊性
作者指出音乐抄袭检测具有两个核心特征:
① 局部相似性(Partial Similarity)
抄袭往往发生在某一小段,而不是整首歌。
② 选择性音乐元素(Selective Element Similarity)
例如: 旋律相同,但编曲、混音、音色完全不同,因此不能只依赖声学特征。
2.4 正式任务定义
给定一首完整歌曲 A:
Task 1:从大规模数据库中找出可能抄袭 A 的歌曲 A′
Task 2:指出 A 与 A′ 哪些片段相似
Task 3:解释相似原因(旋律、和声、节奏等)
3. 方法
整体系统如图所示
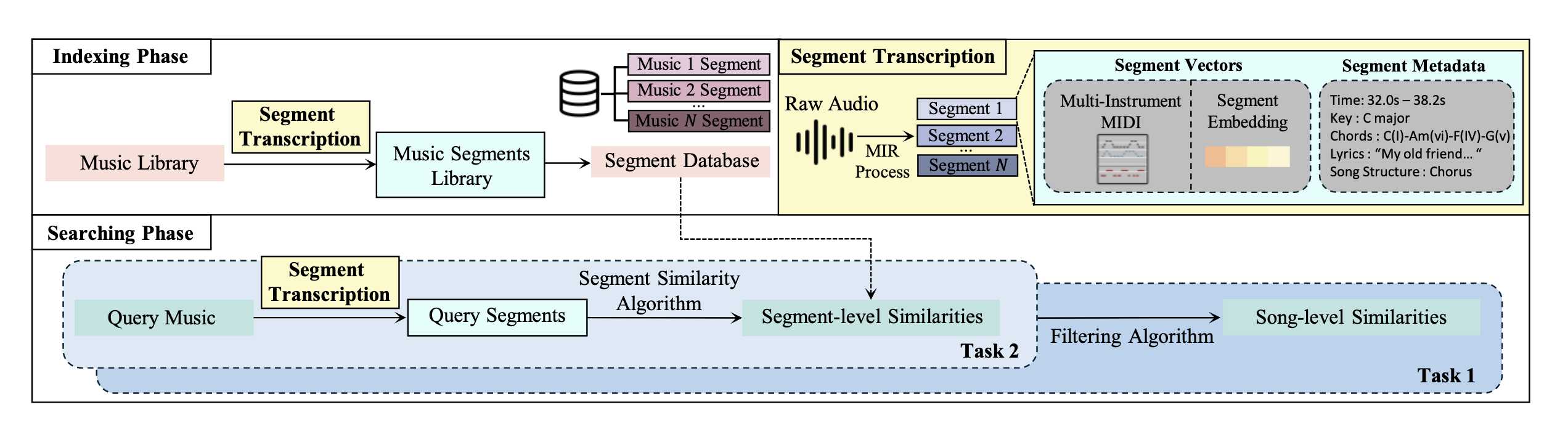
流程包括:
Raw Audio
↓
Segment Transcription
↓
Segment-level Similarity
↓
Song-level Filtering
3.1 Music Segment Transcription
将音频转为结构化片段表示。
使用模型包括:
- Demucs:源分离 [14]
-
All-in-one model:结构分析 [15]
-
AST:人声转录 [16]
-
SheetSage:旋律转录 [17]
-
Harmony Transformer:和声转录 [18]
每个片段包含:
- Multi-instrument MIDI
-
Segment embedding
-
Metadata(调性、和弦、歌词、结构)
片段长度:4 小节
3.2 片段相似度计算方法
方法一:基于音乐知识的算法(Music-domain similarity)
计算:
- Pianoroll 相似度
-
Onset 节奏相似度
-
Chord 相似度
加权组合得到最终分数。
优点: 可解释(支持 Task 3)
缺点:算法方法较传统;难以理论证明有效性
方法二:深度学习方法
- MERT(大规模自监督声学模型)[19]
-
Pianoroll CNN + Siamese [3]
-
Multimodal 双编码器 + cross-attention
作者指出:
MERT 可能受“选择性元素问题”影响,而基于转录的 CNN 方法更鲁棒。
4. 数据集
4.1 SMP Dataset(Similar Music Pair)
论文新构建数据集 :
- 72 对原曲与对比曲
-
包含真实抄袭与翻唱案例
-
每对包含时间戳标注
-
每个相似段落用 acoustic index 标记
-
覆盖多种音乐类型
示例见论文 Table 1

4.2 Covers80 Dataset (80 个翻唱组)
来源:Ellis 2007 [20]
用于:
- 建立未见片段数据库
-
与 CSI 方法对比
5. 实验设计
5.1 实验设置
GPU:NVIDIA RTX 5090
学习率:1e-4
Batch size:32
训练轮数:100
优化器:Adam
5-fold 训练
片段长度:4 bars
5.2 评估指标
片段级(Task 2)
指标:Rec.1s@k
定义:若检索到的片段时间戳与 GT 时间误差 ≤1 秒,视为命中。
实验设置三种规模:
- SMP Timestamps
-
SMP 全片段
-
Full Indices(包含 Covers80)
歌曲级(Task 1)
通过 top-20 片段加权投票。
评估指标:
- mAP
-
MR1(第一个正确结果的平均排名)
6. 实验结果
6.1 片段级结果(Table 2 2601.21260v2)
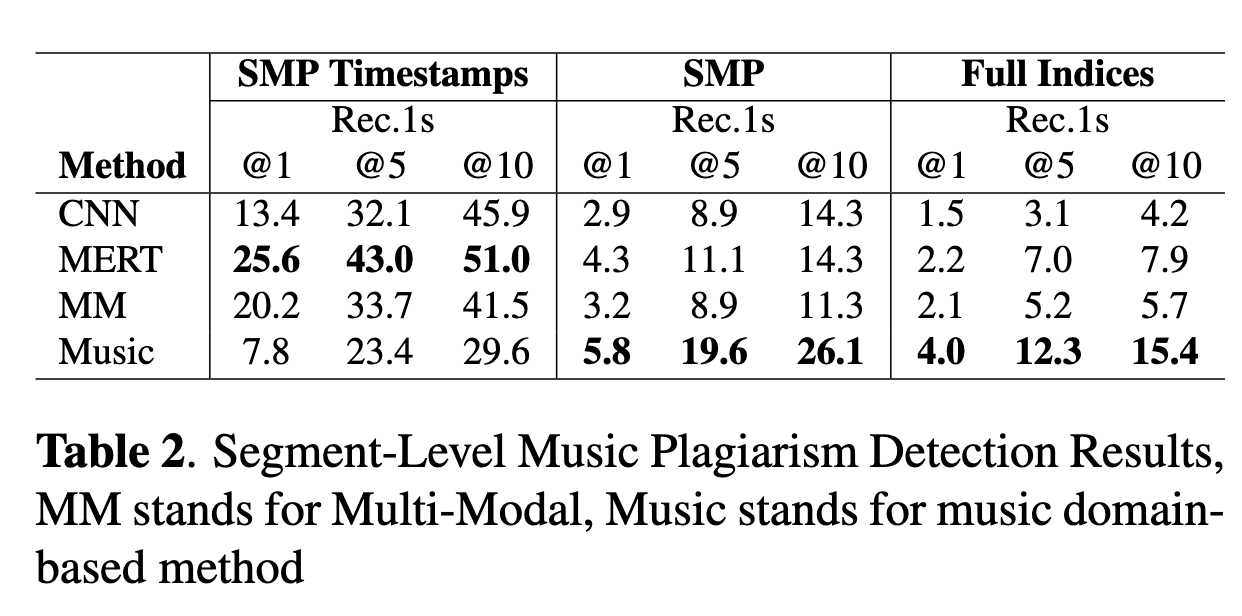
趋势:
- MERT 表现最好
-
多模态方法表现未达预期(可能数据不足)
-
音乐规则方法较稳定
问题:
随着数据库规模扩大,性能显著下降。
说明:
大规模 segment retrieval 可扩展性存在挑战
6.2 歌曲级结果(Table 3 2601.21260v2)
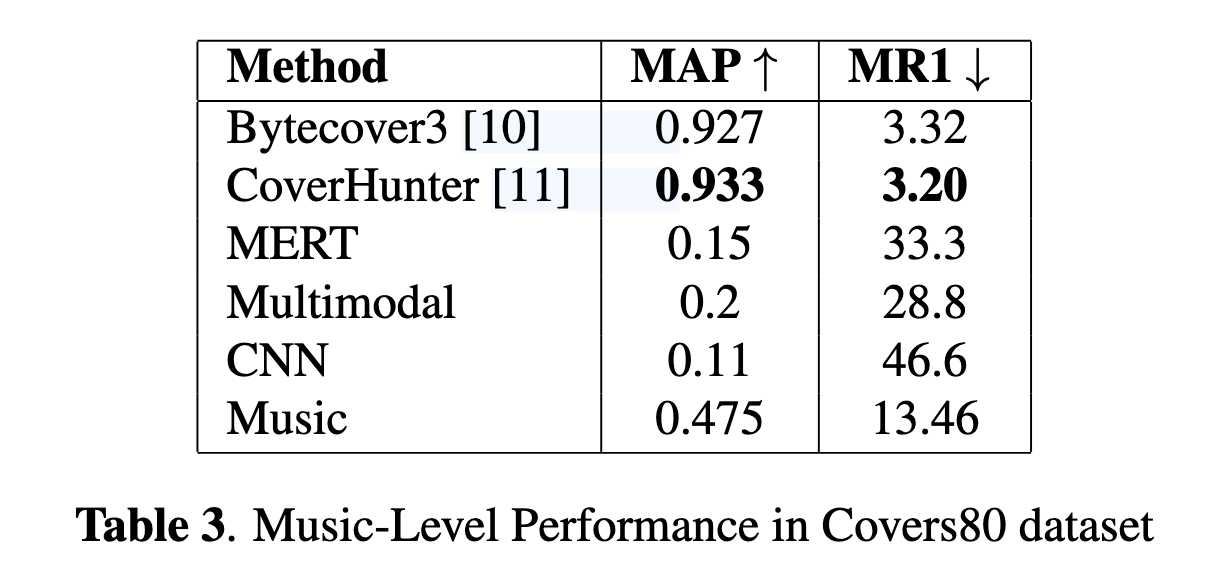
与 CSI 方法对比:
解释:
CSI 优化的是整首相似性,
而抄袭检测强调精确片段定位。
作者强调:
其系统在“可解释性”与“时间定位精度”上具有优势。
7. 结论
本文贡献:
- 明确界定音乐抄袭检测任务(三个子任务)
-
提出基于 segment transcription 的完整 pipeline
-
构建真实案例 SMP 数据集
-
验证 segment-based 框架可行
作者指出该方向仍处于早期阶段。
未来方向:
- 更强相似度度量
-
专用过滤算法
-
规模扩展能力优化
-
更先进 MIR 模型迁移
8. 关键引用文献整理
主题 文献
Siamese CNN 抄袭检测 Park et al., 2022 [3]
MelodySim Lu et al., 2025 [4]
NLP-based 抄袭检测 Malandrino et al., 2022 [5]
Audio Fingerprinting Chang et al., 2021 [12]
Bytecover3 Du et al., 2023 [10]
CoverHunter Liu et al., 2023 [11]
MERT Li et al., 2023 [19]
SheetSage Donahue et al., 2022 [17]
Harmony Transformer Chen et al., 2019 [18]
Covers80 Ellis, 2007 [20]
总体评价
这篇论文的真正创新点在于:
将“音乐抄袭检测”正式从“音乐相似性任务”中剥离出来,给出清晰任务结构。
方法层面不是 SOTA,但:
- 任务定义清晰
- 数据真实
-
强调可解释性
-
强调 segment-level 结构建模
对于 MIR 社区,这是一个问题建模层面的贡献。
About Author
JOANNA JIANG
未来程序员,一般好看,热爱新事物。